




What Is Amazon S3 Archive and How to Use It
If you're dabbling in cloud storage and need a way to store massive amounts of data without breaking the bank, you can try Amazon S3 Archive.
By Crystal / Updated on May 7, 2024
What is an S3 archive?
Amazon S3 Archive is a storage solution within Amazon's Simple Storage Service (S3) designed specifically for long-term data retention and archiving. These services are used to store data that doesn't need frequent access but must be preserved securely for extended periods, often due to compliance, regulatory, or historical reasons.
Amazon S3 Archive uses a tiered storage approach, allowing you to decide how frequently you need to access your data. The key is in its flexibility—you can choose different retrieval options depending on your urgency and budget. If you need quick access, you might opt for expedited retrieval; if you're okay with waiting a bit, standard retrieval will save you even more money. The storage structure is designed to accommodate massive amounts of data while maintaining security and integrity.

Why businesses love Amazon S3 Archive?
It offers a way to offload rarely accessed data without having to pay top dollar. Simply put,
- For starters, it's cost-effective—who doesn't like saving money? When compared to other storage options, S3 Archive is a fraction of the cost, especially if you're storing data for the long haul.
- It's also scalable, meaning you can start with a little and grow into a lot without any headaches.
✍ Tips: Keep in mind that while storage is cheap, frequent data retrieval can add up.
Amazon S3 Glacier vs Amazon S3 Glacier Deep
Amazon S3 (Simple Storage Service) provides a variety of storage classes tailored to different use cases. The primary AWS services designed for archival purposes are Amazon S3 Glacier and Amazon S3 Glacier Deep Archive.
S3 Glacier
- Purpose: Designed for less-frequent data access but with quicker retrieval options. Suitable for backups, compliance, and disaster recovery.
- Retrieval Time: Ranges from expedited (1–5 minutes) to bulk (5–12 hours).
- Cost: Lower than standard S3, higher than S3 Glacier Deep Archive.
- Ideal For: Scenarios where faster data retrieval might be required occasionally, like backup restoration or periodic data analysis.
S3 Glacier Deep Archive
- Purpose: Aimed at long-term, low-cost data storage where retrieval is rare. Ideal for compliance, historical data, and infrequent backups.
- Retrieval Time: Slower, typically 12 to 48 hours.
- Cost: The lowest among S3 storage classes.
- Ideal For: Archiving data for regulatory compliance or long-term retention with minimal access needs. Suitable for large volumes of data that don't need frequent retrieval.
Choosing between S3 Glacier and S3 Glacier Deep Archive depends on your storage needs and access requirements:
- If you need more frequent or faster access to archived data, S3 Glacier might be more suitable.
- If you're focused on cost savings and have low retrieval frequency requirements, S3 Glacier Deep Archive is the better choice.
How to use Amazon S3 Archive?
To set up Amazon S3 Archive, you need to create an Amazon S3 bucket and configure the storage class to Amazon S3 Glacier or Amazon S3 Glacier Deep Archive, depending on your archiving needs.
1. Choose the Objects > Upload > Add files button.
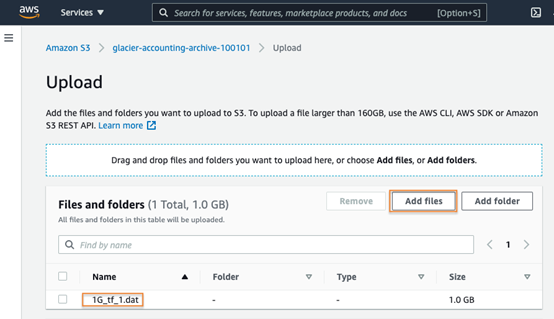
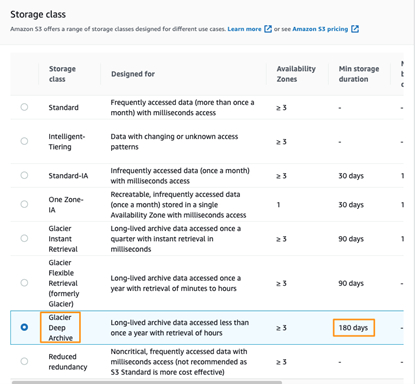
2. In the Properties section, select the S3 storage class you would like to upload your archive to.
* NOTE: Objects stored in many S3 storage classes have minimum object durations associated with them. In this case, uploading the test file to Glacier Deep Archive will result in 180 days of billing, even if it is deleted early. Storing 1 GB in S3 Glacier Deep Archive for 180 days with the retrieval is ~$0.03.
3. You will see the displayed details of the file’s upload status.

4. Once the file upload is complete, you'll see a summary showing whether the operation was successful or if it encountered an error. In this instance, the file uploaded successfully. Click the Close button to proceed.

FAQ about Amazon S3 Archive
Q: How long does data retrieval take in Amazon S3 Archive?
A: Retrieval times for Amazon S3 Archive vary by storage class and retrieval option:
Amazon S3 Glacier Retrieval Times:
- Expedited Retrieval: Typically takes 1 to 5 minutes. This is ideal for urgent data access but comes with a higher cost.
- Standard Retrieval: Generally takes 3 to 5 hours. This option is suitable for regular data retrieval needs.
- Bulk Retrieval: Typically takes 5 to 12 hours. It's the most cost-effective option for retrieving large amounts of data.
Amazon S3 Glacier Deep Archive Retrieval Times:
- Standard Retrieval: Generally, takes 12 to 48 hours. This is the primary retrieval option for S3 Glacier Deep Archive.
- Bulk Retrieval: Usually takes 48 to 96 hours. This is the most economical option for retrieving large volumes of data over a longer period.
Q: Can I integrate Amazon S3 Archive with other AWS services?
A: Absolutely! You can integrate it with other storage classes in S3 and use AWS DataSync for seamless data transfer.
Conclusion
Amazon S3 Archive is a powerful tool for businesses and individuals looking for a cost-effective long-term data storage solution. Its flexible retrieval options, robust security, and scalability make it ideal for a variety of use cases.
While there are some challenges, thoughtful planning and smart management can help you get the most out of this service.

